PdfSearch version-0.2
Carlo B. Bifulco
Abstract
With PdfSearch you can find text strings in an archive of pdf files.
PdfSearch runs on W32 and Unix systems, and can be used from the command
line, through a Tkinter and Pmw based gui (PdfSearchGui) or through
a web browser html interface (PdfSearchServer) . It works by gluing
the Python indexer utility module (http://gnosis.cx/download
by David Mertz) with Xpdf (http://www.foolabs.com/xpdf by Derek
B. Noonburgand). The web browser interface is implemented in CherryPy
(http://www.cherrypy.org by Remi Delon), works in a client-server
fashion and can be easily customized to fit your web site environment.
The latest versions of PdfSearch can be downloaded from http://sourceforge.net/projects/pdfsearch.
Contents
0.1 How it works
0.1.1 Pattern of use
0.2 Interfaces
0.3 Gui interface: PdfSearchGui
0.3.1 Installation
0.3.2 Use
0.4 Web browser interface: PdfSearchServer
0.4.1 Installation
0.4.2 Use
0.4.3 Configuring PdfSearchServer
0.4.4 Customizing PdfSearchServer (source release only)
0.5 Command line interface: PdfSearchCmd.py (source release only)
0.5.1 Use
0.6 Support
0.7 Thanks
0.8 Copyright and Warranty
0.1 How it works
PdfSearch creates a mirror directory (textmirror) inside the search
root directory you are indexing. The textmirror contains a copy of
the entire search root directory tree and has, in the appropriate
location, a the text version of all the indexed pdf files . A text
index database (actually a simple pickled zipped Python dictionary
) is then created from the textmirror.
This means that:
- To index a directory you need to have write permission to it
- Text copies of the pdf files, copies of the directory tree and the
text index database are going to take space on your hard drive space
(on a test I run on a directory containing 313 pdf files for a total
of 78.7 MB the textmirror directory took 27 MB of space)
- Indexing will require time, how much depending again on the dimension
and the number of your pdf files
0.1.1 Pattern of use
Keep your Pdf files in a dedicated directory tree. In this way database
updates will be optimized and as pain free as possible. You can (but
probably should not) use PdfSearch to build an archive of your entire
hard drive; just be aware that this will make database updates extremely
lengthy.
0.2 Interfaces
Three interfaces are available, respectively:
- A local GUI interface (PdfSearchGui)
- A server web interface (PdfSearchServer)
- A command line interface (command.py)
0.3 Gui interface: PdfSearchGui
0.3.1 Installation
*nix (Unix or Linux)
The program has the following dependencies, which have to be properly
in place, for it to run:
Once you have these working, download PdfSearch.tar.gz, and, from
a shell, type:
-
tar -xzvf PdfSearch.tar.gz
cd PdfSearch
python ./PdfSearchGui.py
W32
If you downloaded the executable PdfSearchGui.exe:
- Run the installer by double clicking 'PdfSearchGui.exe'
If you downloaded the source and you have Python 2.2 and Pmw installed
and properly configured unzip the release and:
- Start the program by double clicking on the 'PdfSearchGui.py' file
in the PdfSearch main directory
- Or enter from the command line the following:
-
cd PdfSearch
python PdfSearchGui.py
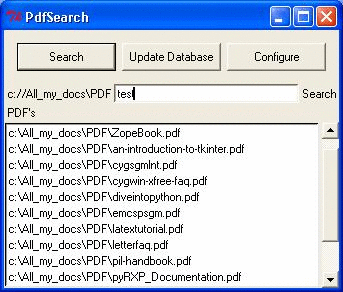
Create your pdf database
Clicking on the Config button with the left mouse button will open
a tree view of your hard drive. Choose the search root directory and
press the submit button. Select the updatedb button with the mouse.
Relax, as the first run may take a lot of time, depending on the number
of pdf files needing to be indexed. All the pdf files present in the
selected dir and in it's subdirs will now be available for text searches.
Search and View
Enter the text and press either enter or double click on the search
button. Words divided by a spaces are considered as being united by
a logical AND.
A list of all the files matching your search entry will appear. Just
double click on the ones you would like to review .
0.4 Web browser interface: PdfSearchServer
PdfSearchServer offers the same features as PdfSearch, but through
an html web browser interface and in a client-server fashion.
0.4.1 Installation
*nix (Unix or Linux)
PdfSearchServer.py is included in the PdfSearch source release.
The program has the following dependencies, which have to be properly
in place, for it to run:
Once you have these working you can unpack the tarball with:
-
tar -xzvf PdfSearch.tar.gz
To start the server:
-
cd PdfSearch
python ./PdfSearchServer.py
The server should start working, serving web pages at port 8000 and
indexing as search root directory by default the PdfSearch directory
. Startup may be slow as PdfSearchServer re-indexes all your pdf files
every time it starts. Point your browser on http://localhost:8000
and you should be able to see the PdfSearchServer web interface.
W32
If you downloaded the executable PdfSearchGui.exe:
- Run the installer by double clicking 'PdfSearchGui.exe'. The PdfSearchGui
icon will appear in the desktop and in the startup menu.
If you downloaded the source and you have Python 2.2 installed configured:
- Unzip the release
- Start the program by double clicking on the 'PdfSearchServer.py' file
in the PdfSearch main directory.
- Or enter from the command line the following:
-
cd PdfSearch
python PdfSearchServer.py
-
The server should start working, serving web pages at port 8000 and
indexing as search root directory by default the PdfSearch directory
. Startup may be slow as PdfSearchServer re-indexes all your pdf files
every time it starts. Point your browser on http://localhost:8000
and you should be able to see the PdfSearchServer web interface.

Search and View
Enter the text and press either enter or double click on the search
button. Words divided by a spaces are considered as being united by
a logical AND.
A list of all the files containing the selected words will appear.
Just double click on the names of the files you would like to view
.
0.4.3 Configuring PdfSearchServer
By default PdfSearchServer will be serving content on port 8000 and
will consider the PdfSearchServer directory as the search root. You
can however modify both parameters. To do this you have to edit the
PdfSearchServer.cfg configuration file, located in the PdfSearch main
directory.
E.g., let's say you would like to configure PdfSearchServer to serve
content on port 80 (the default of most web browsers) and you have
your pdf repository in c:/All_my_docs/PDF and you have already indexed
it's content, and you do not want to re-index the search root directory
again. You will have to change the PdfSearchServer.cfg file as follows:
From:
-
[staticContent]
static=./static
[server]
socketPort=8000
[PdfSearch]
working_dir=Here_your_path
updatedb=1
To:
-
[staticContent]
static=./static
[server]
socketPort=80
[PdfSearch]
working_dir=c:/All_my_docs/PDF
updatedb=0
Restart the server; web content will now be available on port 80 ,
your search root will be c:/All_my_docs/PDF and it will not be re-indexed
at every startup.
0.4.4 Customizing PdfSearchServer (source release only)
You can completely modify the user interface, editing the html files
present in the PdfSearch static directory (home.html, results.html,
noresults.html, configure.html), using any WYSIWYG editor. Just remember
to:
- Leave the <py-xyz> tags intact
- Leave a link to license.html in each html page
- Do not alter license.html
To make the changes effective you will have to recompile the PdfSearch.cpy
file, so to produce an updated PdfSearchServer.py file. Briefly, this
involves running the following from the command line:
-
python cherrypy.py PdfSearch.cpy
The new PdfSearchServer.py will now serve your personalized html interface.
Please refer to CherryPy's (http://www.cherrypy.org) documentation
for the details of the process.
0.5 Command line interface: PdfSearchCmd.py (source release only)
Change directory to the PdfSearch directory containing ``PdfSearchCmd.py''.
You will need to have pdftotext in your search path.
From the commands line run:
-
python PdfSearchCmd.py
with the following options:
-h/-help: this message
-u/-update: update text and pdf database
-f/-find: interactive search; type quit/q to exit
-d=directory/-dir: search root directory
0.6 Support
The author can be reached at mailto:carlo_bif@yahoo.com. Any
feedback welcomed.
0.7 Thanks
Thanks to:
- Derek B. Noonburgand, author of pdftotext
- David Mertz, author of of the indexer module
- Charles E. "Gene" Cash, author of the tree Tkinter
widget
- Remi Delon, author of CherryPy
0.8 Copyright and Warranty
PdfSearch: a simple pdf text search utility with Gui, Web and command
line interfaces.
Copyright (C) 2002 Carlo B. Bifulco
This program is free software; you can redistribute it and/or modify
it under the terms of the GNU General Public License as published
by the Free Software Foundation; either version 2 of the License,
or (at your option) any later version.
This program is distributed in the hope that it will be useful, but
WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY
or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License
for more details.
You should have received a copy of the GNU General Public License
along with this program; if not, write to the Free Software Foundation,
Inc., 59 Temple Place, Suite 330, Boston, MA 02111-1307 USA
File translated from
TEX
by
TTH,
version 3.13.
On 17 Sep 2002, 14:39.